标签 - 算法
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得分布式哈希(DHT)可以在P2P环境中真正得到应用。
一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
1、平衡性(Balance): 平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
2、单调性(Monotonicity): 单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3、分散性(Spread): 在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4、负载(Load): 负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
在分布式集群中,对机器的添加删除,或者机器故障后自动脱离集群这些操作是分布式集群管理最基本的功能。如果采用常用的hash(object)%N算法,那么在有机器添加或者删除后,很多原有的数据就无法找到了,这样严重的违反了单调性原则。接下来主要讲解一下一致性哈希算法是如何设计的:
环形Hash空间
按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。如下图
把数据通过一定的hash算法处理后映射到环上
现在我们将obj

本文cmd地址:经典检索算法:BM25原理
bm25 是什么?
bm25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法,再用简单的话来描述下bm25算法:我们有一个query和一批文档Ds,现在要计算query和每篇文档D之间的相关性分数,我们的做法是,先对query进行切分,得到单词$q_i$,然后单词的分数由3部分组成:
- 单词$q_i$和D之间的相关性
- 单词$q_i$和D之间的相关性
- 每个单词的权重
最后对于每个单词的分数我们做一个求和,就得到了query和文档之间的分数。
bm25 解释
讲bm25之前,我们要先介绍一些概念。
二值独立模型 BIM
BIM(binary independence model)是为了对文档和query相关性评价而提出的算法,BIM为了计算$P(R|d,q)$,引入了两个基本假设:
假设1
一篇文章在由特征表示的时候,只考虑词出现或者不出现,具体来说就是文档d在表示为向量$\vec x=(x_1,x_2,...,x_n)$,其中当词$t$出现在文档d时,$x_t=1$,否在$x_t=0$。
假设2
文档中词的出现与否是彼此独立的,数学上描述就是$P(D)=\sum_{i=0}^n P(x_i)$
有了这两个假设,我们来对文档和query相关性建模:
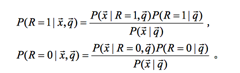
其中

接着因为我们最终得到的是一个排序,所以,我们通过计算文档和query相关和不相关的比率,也可得文档的排序,有下面的公式:

其中


由于每个 xt 的取值要么为 0 要么为 1,所以,我们可得到:
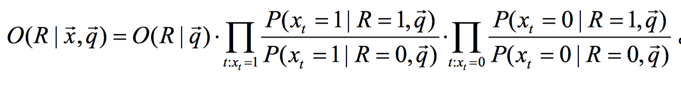
我们接着引入一些记号:


于是我们就可得到:

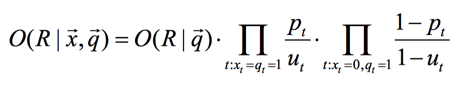
我们接着做下面的等价变换:
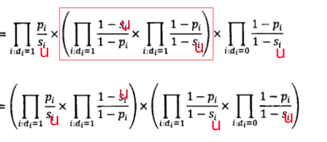

此时,公式中
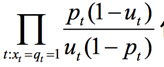

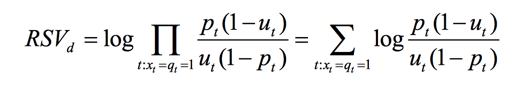
定义单个词的ct

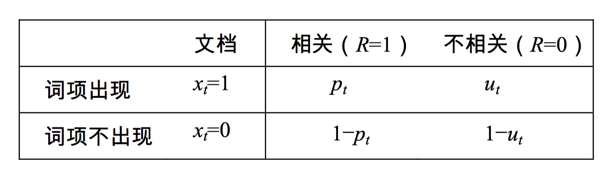
下一步我们要解决的就是怎么去估计pt和ut,看下表:

其中dft是包含词t的文档总数,于是

此时词t的ct值是:
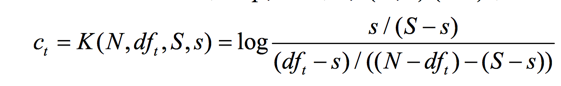
为了做平滑处理,我们都加上1/2,得到:
最早拥有排序概念的机器出现在 1901 至 1904 年间由 Hollerith 发明出使用基数排序法的分类机,此机器系统包括打孔,制表等功能,1908 年分类机第一次应用于人口普查,并且在两年内完成了所有的普查数据和归档。
Hollerith 在 1896 年创立的分类机公司的前身,为电脑制表记录公司(CTR)。他在电脑制表记录公司(CTR)曾担任顾问工程师,直到1921年退休,而电脑制表记录公司(CTR)在1924年正式改名为IBM。
---- 摘自《维基百科 - 插入排序》
期中已到,期末将至。《算法设计与分析》的“预习”阶段藉此开始~。在众多的算法思想中,如果你没有扎实的数据结构的功底,不知道栈与队列,哈希表与二叉树,不妨可以从排序算法开始练手。纵观各类排序算法,常见的、经典的排序算法将由此篇引出。
排序算法的输出必须遵守的下列两个原则:
- 输出结果为递增序列(递增是针对所需的排序顺序而言)
- 输出结果是原输入的一种排列、或是重组

十大经典的排序算法及其时间复杂度和稳定性如上表所示。判断一个排序算法是否稳定是看在相等的两个数据排序算法执行完成后是否会前后关系颠倒,如若颠倒,则称该排序算法为不稳定,例如选择排序和快速排序。
排序前:(4, 1) (3, 1) (3, 7)(5, 6)
排序后:(3, 1) (3, 7) (4, 1) (5, 6) (稳定,维持次序)
排序后:(3, 7) (3, 1) (4, 1) (5, 6) (不稳定,次序被改变)
00.交换两个整数的值
接下来十个经典排序算法的详细探讨缺少不了交换两个整数值的掌握,这里回顾一下其中三种方交换法:用临时变量交换两个整数的值(SwapTwo_1)、不用第三方变量交换两个整数的值(SwapTwo_2)、使用位运算交换两个整数的值(SwapTwo_3)。其中用临时变量交换两个整数的值效率最高,后俩者只适用于内置整型数据类型的交换,并不高效。
void SwapTwo_1 (int *a, int* b) {
int temp;
temp = *a;
*a = *b;
*b = temp;
}void SwapTwo_2 (int *a, int *b) {
*a = *a + *b;
*b = *a - *b;
*a = *a - *b;
}void SwapTwo_3